
In the rapidly evolving world of artificial intelligence, large language models (LLMs) have become the cornerstone of generative AI applications. These models, which power everything from chatbots to content generation tools, rely on vast amounts of training data to improve their performance. However, a concerning trend is emerging: the rate at which AI companies are consuming training data far outpaces the creation of new, publicly available information. This development raises a critical question: Are we on the brink of a data scarcity crisis in AI?
The Exponential Growth of Data Consumption in AI Training
The AI industry has witnessed an unprecedented surge in the amount of data used for training language models. This trend is clearly illustrated by the exponential increase in the number of tokens used for LLM training over the years:
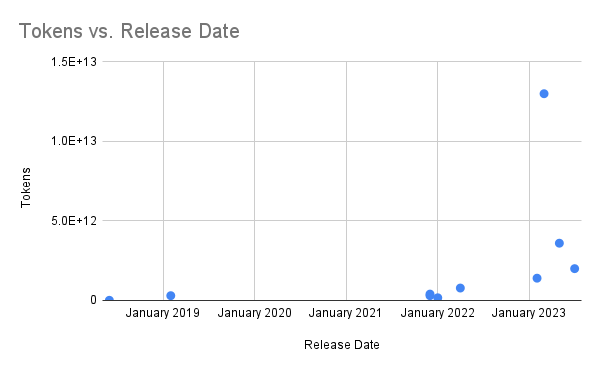
This steep rise in data consumption has been the primary driver of progress in AI capabilities. However, experts are now warning that this approach may not be sustainable in the long term.
The Impending Data Drought: A Ticking Clock for AI Companies
Research conducted by Epoch AI paints a sobering picture of the future of AI training data availability. According to their analysis, tech companies are on track to exhaust publicly available data for LLM training between 2026 and 2032. This timeline varies depending on how models are scaled and trained.
Epoch AI researchers note:
"If models are trained compute-optimally, there is enough data to train a model with 5e28 floating-point operations (FLOP), a level we expect to be reached in 2028. But recent models, like Llama 3, are often 'overtrained' with fewer parameters and more data to make them more compute-efficient during inference."
This projection is particularly alarming when we consider that in just about a decade since the inception of generative AI, companies will have depleted the freely available human-generated information on the internet. This includes articles, blogs, social media discussions, academic papers, and more.
Moreover, the situation isn't much better when considering other data modalities. Current stocks of video and image data are not sufficient to prevent a data bottleneck. Here's a breakdown of the estimated token equivalents for various data sources:
Common Crawl: 130 trillion tokens
Indexed web: 510 trillion tokens
The whole web: 3,100 trillion tokens
Images: 300 trillion tokens
Video: 1,350 trillion tokens
With publicly available web-scraped data forming the foundation of LLM training, the looming scarcity poses a significant challenge for AI companies. But is the situation as dire as it seems, and what can be done to address this impending crisis?
Strategies for Scaling LLMs in a Data-Scarce Future
As the AI industry faces the prospect of running out of public training data, experts have proposed several strategies to overcome this challenge. These approaches involve tapping into offline information, leveraging synthetic data, and improving LLM efficiency.
1. Striking Deals with Publishers for Non-Public Data
One promising avenue is for AI companies to negotiate agreements with publishers and content creators for access to non-public, paywalled, or non-indexed data. This approach is already gaining traction in the industry:
Google has entered into a $60 million deal with Reddit for access to its data.
OpenAI has signed agreements with several major publishers, including the Associated Press, Axel Springer, Le Monde, Prisa Media, and the Financial Times.
Other potential sources of high-quality data include:
Offline information: Books, manuscripts, and magazines that can be digitized and licensed.
Research data: Genomics, financial, and scientific databases that offer specialized, high-quality information.
Deep web data: Non-indexed content from social media platforms and instant messaging services, although privacy concerns must be carefully addressed.
2. Advancing LLM Architecture and Training Techniques
Improving the efficiency of LLMs to achieve better performance with less data is another crucial strategy. Several approaches show promise in this area:
Reinforcement learning techniques have demonstrated gains in sample efficiency.
Data enrichment and high-quality sample filtering can optimize Pareto efficiency, leading to improved LLM performance and training efficiency.
Transfer learning, where models are pre-trained on data-rich tasks before being fine-tuned for specific applications, can help maximize the utility of available data.
Sunil Ramlochan, enterprise AI strategist and founder of PromptEngineering.org, emphasizes the importance of systematic experimentation:
"Determining how much data is needed to train a language model is an empirical question best answered through systematic experimentation at different orders of magnitude. By measuring model performance across varying data scales and considering factors like model architecture, task complexity, and data quality, NLP practitioners can make informed decisions about resource allocation and continuously optimize their language models over time."
3. Harnessing the Power of Synthetic Data
As real-world data becomes scarcer and more challenging to obtain, synthetic data is emerging as a potential solution. Gartner predicts that by 2026, 75% of businesses will use generative AI to create synthetic customer data.
Synthetic data offers several advantages:
It can be generated algorithmically, creating new scenarios for LLMs to learn from.
It retains similar mathematical patterns to real data without containing sensitive information.
Large amounts of synthetic data can be created quickly, enabling faster development cycles.
Techniques like DeepMind's Reinforced Self-Training (ReST) for Language Modeling show promise in this area. However, synthetic data also has limitations:
It may produce biased responses, inaccuracies, or hallucinations.
There are potential security and privacy risks associated with its use.
Synthetic data may fail to capture the nuances of real-world scenarios.
Researchers have also raised concerns about the potential for "Mad Autophagy Disorder" (MAD) in LLMs trained primarily on synthetic data. This phenomenon could lead to a progressive decrease in the quality or diversity of model outputs over time.
Conclusion: Navigating the Challenges Ahead
As the AI industry faces the prospect of exhausting publicly available training data, companies and researchers must adapt their strategies to ensure continued progress. By exploring alternative data sources, improving model efficiency, and carefully leveraging synthetic data, the field can work towards sustainable growth in the face of potential data scarcity.
The coming years will be crucial in determining how well the AI industry can navigate these challenges. As we approach the limits of freely available data, the ability to innovate and find new solutions will be more important than ever. The future of AI may well depend on how effectively we can balance the need for vast amounts of training data with the realities of a finite digital landscape.
References
https://www.spiceworks.com/tech/artificial-intelligence/articles/is-llm-training-data-running-out/
https://www.theverge.com/2024/1/4/24025409/openai-training-data-lowball-nyt-ai-copyright
https://www.euronews.com/next/2024/06/27/publishers-are-signing-big-ticket-deals-with-openai-but-at-what-cost



